

Intelligenza Artificiale su misura: Sviluppare chatbot personalizzati e veloci con Prompt-Tuning e RAG
Due alternative al fine-tuning per sviluppare chatbot personalizzati più velocemente
di Simone Eandi, AI Engineer di Intesa, a Kyndryl Company

I Large Language Models (LLM), come il famoso ChatGPT, stanno stupendo il mondo con la loro capacità di rispondere a qualsiasi domanda. Ma fino a che punto possiamo fidarci delle loro risposte? E cosa possiamo fare per migliorarli? Ce ne parla in questo articolo Simone Eandi.
![]()
In questo articolo scoprirai:
I Large Language Models (LLM), come ChatGPT per citare il più famoso, stupiscono per la loro abilità nel rispondere a qualsiasi domanda, quasi fossero esseri onniscienti. La loro capacità di rispondere a molte domande deriva dall’enorme quantità di dati sui quali sono stati allenati.
Tuttavia, questa “onniscienza” ha dei limiti. Se interrogati su un argomento nuovo, non presente nei dati di allenamento, perché molto specifico o successivo alla data di sviluppo, l’AI potrebbe non sapere come rispondere, o ancor peggio potrebbe generare una risposta completamente inventata, priva di fondamento e potenzialmente dannosa.
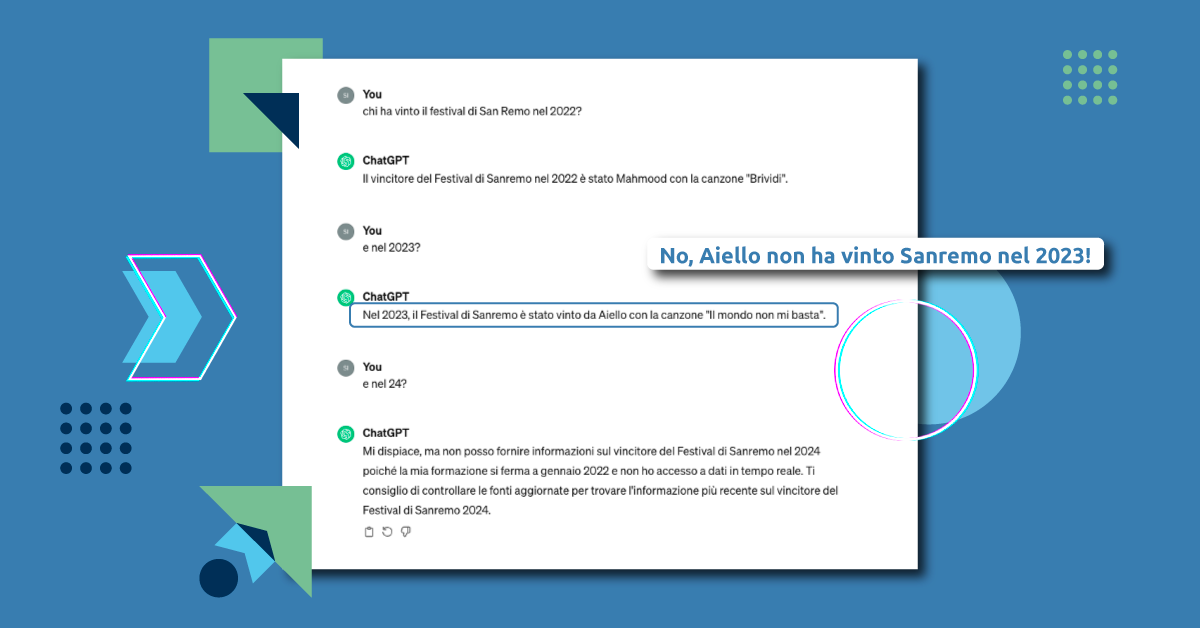
La versione usata di ChatGPT è stata allenata nel 2022 e non ha quindi accesso alle informazioni relative ai vincitori di Sanremo nel 2023 e nel 2024. Per il 2024 ci avvisa che non è in grado di fornire una risposta. Per il 2023, invece, prova a fare il “furbo” inventandosi una risposta piuttosto fantasiosa.
Ma allora, se un’azienda utilizza un chatbot basato su ChatGPT per fornire assistenza sui suoi servizi, come è possibile che questo sia in grado di dare informazioni accurate se non ha mai “visto” tali servizi durante l’allenamento?
Fine-tuning e prompt-tuning
Una soluzione possibile è l’utilizzo di tecniche di fine-tuning e prompt-tuning. Allenare da zero una LLM ha costi proibitivi e richiede enormi quantità di dati, che spesso non sono disponibili. Quindi, anziché partire da zero, si parte da un modello preaddestrato e lo si raffina ulteriormente sui dati di interesse. Questa pratica, chiamata fine-tuning, riduce i costi ed è accessibile a molti; tuttavia, rimane un processo impegnativo e non sempre è la soluzione ottimale.
Un’alternativa è il prompt-tuning. Oltre alla domanda posta dall’utente, viene fornito al modello un prompt che contiene le informazioni necessarie per rispondere alla domanda. Il prompt include istruzioni su come il modello dovrebbe comportarsi e il contesto necessario per elaborare le risposte.
Ad esempio, consideriamo un chatbot che fornisce assistenza sugli errori di un’applicazione; il prompt potrebbe essere:
“Sei un assistente che deve aiutare gli utenti della piattaforma XYZ a risolvere gli errori. Ecco la descrizione dei possibili codici di errore della piattaforma XYZ:
- Errore 2130: …
- Errore 5470: …”
Una volta individuato un prompt adeguato per l’applicazione, il gestore del servizio svolge il ruolo di intermediario tra l’utente e il modello effettivo (es.ChatGPT): per ogni domanda posta dall’utente dovrà prima aggiungervi il prompt e poi mandare il tutto al modello per generare la risposta.
Utilizzare un prompt ad-hoc consente di personalizzare il comportamento dell’IA senza richiedere un ulteriore addestramento, accelerando notevolmente i tempi di sviluppo. Tuttavia, questo approccio presenta uno svantaggio significativo: è necessario includere il prompt ogni volta che si invia una domanda all’IA, aumentando sia i costi che i tempi di elaborazione (specialmente se il modello è a pagamento per l’uso). Inoltre, esiste un limite massimo alla quantità di caratteri che possono essere inclusi nell’input, il che potrebbe rendere impossibile fornire tutto il contesto necessario nel prompt (come nel caso della descrizione dei codici di errore nel precedente esempio).
Retrieval Augmented Generation
Il Retrieval Augmented Generation (RAG) è una tecnica che amplia le capacità generative di un LLM connettendolo a una fonte esterna di conoscenza, come un database o un insieme di documenti testuali. In un sistema RAG, quando arriva una domanda, vengono recuperate dall’archivio esterno le informazioni più pertinenti alla domanda specifica e vengono aggiunte al prompt prima di essere passate al modello per generare la risposta. Questo consente al modello di accedere a fonti di dati molto ampie senza necessità di ulteriore addestramento, fornendo solo le parti rilevanti per volta e evitando sovraccarichi di informazioni inutili.
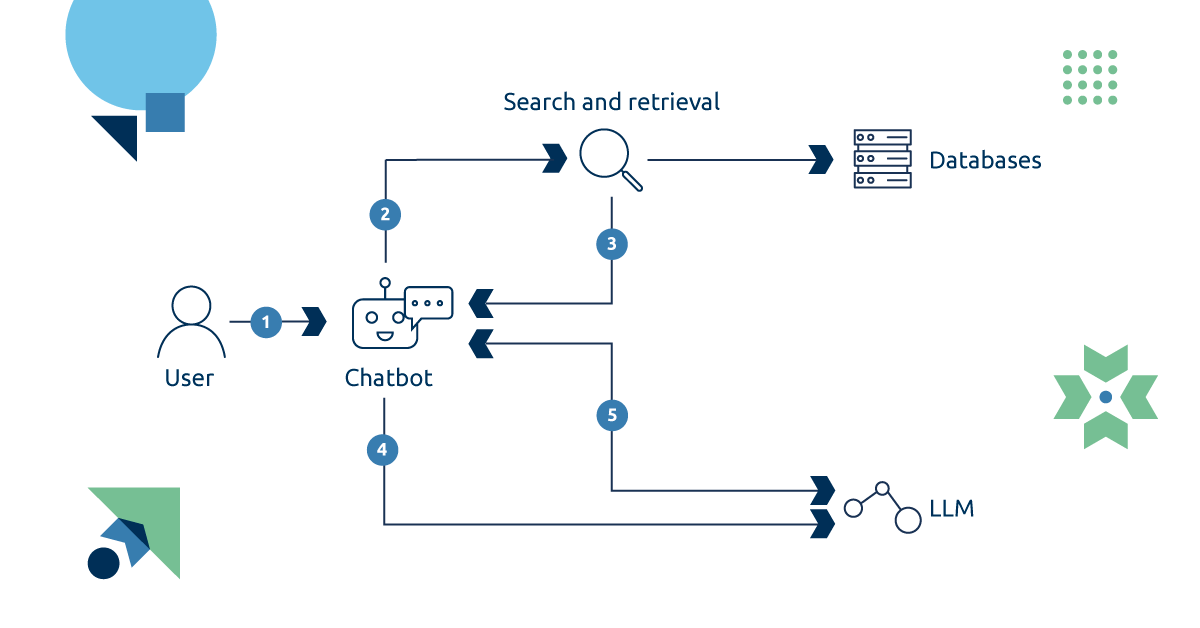
Sebbene esistano approcci più avanzati per lavorare con immagini o database relazionali, l’uso principale della RAG è con i documenti testuali. L’ aspetto cruciale in questo caso è la capacità di estrarre solo i pezzi di testo rilevanti dalla fonte di dati, e per farlo ci si affida in genere ai database vettoriali per archiviare i dati. In questo tipo di database, diventati popolari grazie alla diffusione dei LLM, i documenti sono suddivisi in frammenti di testo più piccoli e per ognuno viene calcolato un embedding, ossia una sua rappresentazione numerica significativa. Gli embeddings fungono da indici per recuperare i dati: quando viene eseguita una query di ricerca, il suo embedding viene calcolato e il database restituisce i dati con l’embedding più simile a quello della query. Questo processo può essere paragonato a tradurre il testo in un’altra lingua nella quale sia più facile per un algoritmo riconoscere porzioni di testo simili.
Applicazioni RAG
La RAG è rapidamente diventata una tecnica fondamentale nello sviluppo di diverse applicazioni di AI generativa (GenAI), consentendo la creazione rapida di assistenti in grado di rispondere in modo preciso e dettagliato alle domande. Tra i casi d’uso più comuni ci sono sistemi di Q&A avanzati, motori di ricerca generativi e sistemi di raccomandazione più personalizzati e dettagliati.
In Intesa, diverse applicazioni basate su RAG sono in fase di sviluppo, inclusi un assistente interno per estrarre informazioni dalla documentazione tecnica e un chatbot conversazionale per l’estrazione di KPI dai database SQL della Control Tower Light.
Conclusioni
Come abbiamo visto, l’uso combinato di prompt-tuning e RAG consente lo sviluppo di chatbot altamente specializzati e con accesso a dati specifici, partendo da un modello pre addestrato. Sebbene queste tecniche siano valide alternative al fine-tuning, non dovrebbero essere considerate esclusivamente come suoi sostituti. Il fine-tuning, infatti, rimane una tecnica molto utile, ad esempio per insegnare al modello un lessico specifico, e può essere massimizzato se combinato con le tecniche precedenti.



